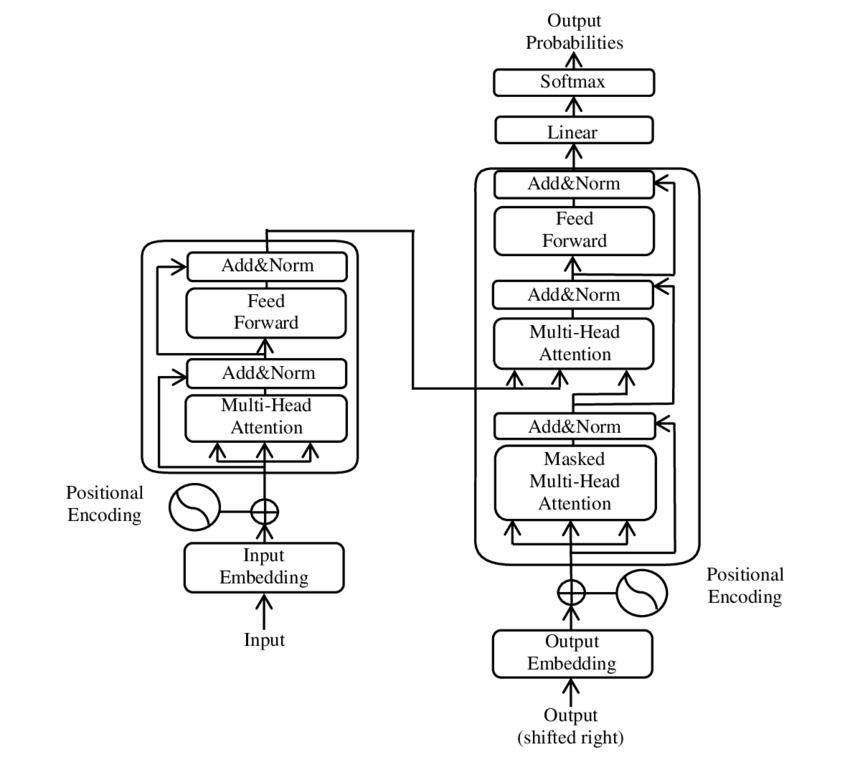
The guts of a Transformer :-
Steps in a Transformer Encoder:
Dimensions = Batch (N) Sentence Length (T) Heads (H) Word Dimension (D)
1. Produce Query, Key Values
QKV Wgts (NxTxHxD) x Input - Encoded sentence (NxTxD)
= QKV (NxTxHxD)
2. SoftMax, Concatonate and Dimensionality reduction
Z (NxTxHxD) = SoftMax((Q * Kt) / DK)*V
Z (NxTxHxD) x WgtZ(HxDxD) = Z (NxTxD)
3. Add and Norm
Z = Z (NxTxD) + Input (NxTxD)
Z = Z-Mean / StdDev
4. RELU Feedforward using Hidden Layer Size (H) (2 Layers)
Hidden (HxNxT) = FeedForward Z (DxNxT) x W(HxD)
Output (DxNxT) = Feedforward Hidden (HxNxT) x W(DxH)
*H(Layer Size) = 4 * D(Model) e.g 2048 = 512 * 4
or 1 Layer
Output (DxNxT) = Feedforward Z (DxNxT) x W(DxD)
H = D
5. Add and Norm
Output (DxNxT) = Output (DxNxT) + Input (DxTxN)
Final Output = Output-Mean / StdDev
Dimensions = Batch (N) Sentence Length (T) Heads (H) Word Dimension (D)
1. Produce Query, Key Values
QKV Wgts (NxTxHxD) x Input - Encoded sentence (NxTxD)
= QKV (NxTxHxD)
2. SoftMax, Concatonate and Dimensionality reduction
Z (NxTxHxD) = SoftMax((Q * Kt) / DK)*V
Z (NxTxHxD) x WgtZ(HxDxD) = Z (NxTxD)
3. Add and Norm
Z = Z (NxTxD) + Input (NxTxD)
Z = Z-Mean / StdDev
4. RELU Feedforward using Hidden Layer Size (H) (2 Layers)
Hidden (HxNxT) = FeedForward Z (DxNxT) x W(HxD)
Output (DxNxT) = Feedforward Hidden (HxNxT) x W(DxH)
*H(Layer Size) = 4 * D(Model) e.g 2048 = 512 * 4
or 1 Layer
Output (DxNxT) = Feedforward Z (DxNxT) x W(DxD)
H = D
5. Add and Norm
Output (DxNxT) = Output (DxNxT) + Input (DxTxN)
Final Output = Output-Mean / StdDev