prompt and output text from more than one llm by
normalizing ranks of each different output for the same prompt from
more than one llm
the output text is rated using human feedback
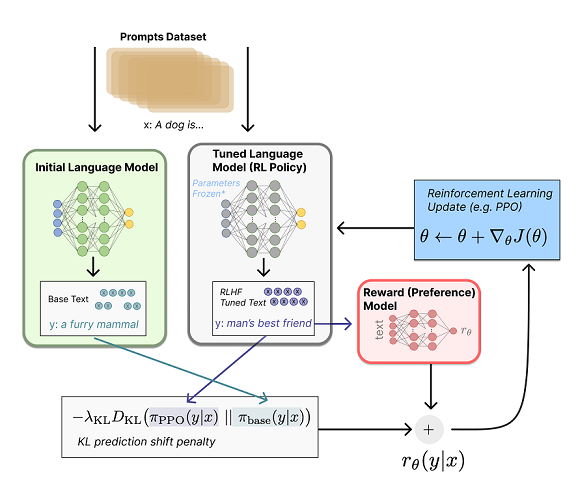
Reward Model:
Input dim(batch * input_prompt(seqlen)+output_text(seqlen)
Output dim(batch * Scalar Reward)
the reward model is then used alongside a pretrained llm to
train an llm using reinforcement learning
1. policy = llm1 generates text(action) from prompt(observation)
2. reward = reward model + constraint(penalty)
first a penalty if computed when comparing the outputs of each
llm
the penalty is included in the reward for each generated output
tokensLLM = per token probabilitys for prompt
Rkl = KL(tokensLLM1,tokensLLM2)
R0 = Scalar output of Reward Model for Prompt and Generated Text
R = R0 - lamda *Rkl